Machine Learning Algorithms
Machine Learning
Algorithms
Machine Learning algorithms are the programs
that can learn the hidden patterns from the data, predict the output, and
improve the performance from experiences on their own. Different algorithms can
be used in machine learning for different tasks, such as simple linear
regression that can be used for prediction problems like stock
market prediction, and the KNN algorithm can be used for
classification problems.
In this topic, we will see the overview of
some popular and most commonly used Machine Learning Algorithms along with
their use cases and categories.
Types of Machine Learning Algorithms
Machine Learning Algorithm can be broadly
classified into three types:
1.
Supervised
Learning Algorithms
2.
Unsupervised
Learning Algorithms
3.
Reinforcement
Learning algorithm
The below diagram illustrates the different
ML algorithm, along with the categories:
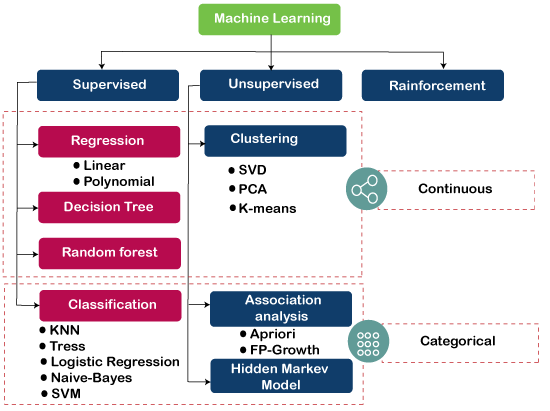
Supervised
learning is the types of machine learning in which machines are trained using
well "labelled" training data, and on basis of that data, machines
predict the output. The labelled data means some input data is already tagged
with the correct output.
In
supervised learning, the training data provided to the machines work as the
supervisor that teaches the machines to predict the output correctly. It
applies the same concept as a student learns in the supervision of the teacher.
Supervised
learning is a process of providing input data as well as correct output data to
the machine learning model. The aim of a supervised learning algorithm is to find
a mapping function to map the input variable(x) with the output variable(y).
In the
real-world, supervised learning can be used for Risk Assessment, Image
classification, Fraud Detection, spam filtering, etc.
How Supervised Learning Works?
In
supervised learning, models are trained using labelled dataset, where the model
learns about each type of data. Once the training process is completed, the
model is tested on the basis of test data (a subset of the training set), and
then it predicts the output.
The
working of Supervised learning can be easily understood by the below example
and diagram:
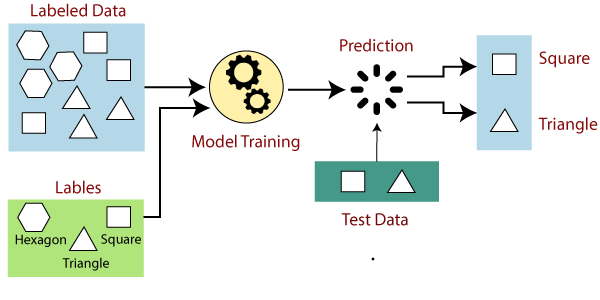
Suppose
we have a dataset of different types of shapes which includes square,
rectangle, triangle, and Polygon. Now the first step is that we need to train
the model for each shape.
- If the given shape has four
sides, and all the sides are equal, then it will be labelled as a Square.
- If the given shape has three
sides, then it will be labelled as a triangle.
- If the given shape has six
equal sides then it will be labelled as hexagon.
Now,
after training, we test our model using the test set, and the task of the model
is to identify the shape.
The
machine is already trained on all types of shapes, and when it finds a new
shape, it classifies the shape on the bases of a number of sides, and predicts
the output.
Steps Involved in Supervised Learning:
- First Determine the type of
training dataset
- Collect/Gather the labelled
training data.
- Split the training dataset
into training dataset, test dataset, and validation dataset.
- Determine the input features
of the training dataset, which should have enough knowledge so that the
model can accurately predict the output.
- Determine the suitable
algorithm for the model, such as support vector machine, decision tree,
etc.
- Execute the algorithm on the
training dataset. Sometimes we need validation sets as the control
parameters, which are the subset of training datasets.
- Evaluate the accuracy of the
model by providing the test set. If the model predicts the correct output,
which means our model is accurate.
Types of supervised Machine learning Algorithms:
Supervised
learning can be further divided into two types of problems:
1.
Regression
Regression
algorithms are used if there is a relationship between the input variable and
the output variable. It is used for the prediction of continuous variables,
such as Weather forecasting, Market Trends, etc. Below are some popular
Regression algorithms which come under supervised learning:
- Linear Regression
- Regression Trees
- Non-Linear Regression
- Bayesian Linear Regression
- Polynomial Regression
2.
Classification
Classification
algorithms are used when the output variable is categorical, which means there
are two classes such as Yes-No, Male-Female, True-false, etc.
Spam
Filtering,
- Random Forest
- Decision Trees
- Logistic Regression
- Support vector Machines
Advantages of Supervised learning:
- With the help of supervised
learning, the model can predict the output on the basis of prior
experiences.
- In supervised learning, we
can have an exact idea about the classes of objects.
- Supervised learning model
helps us to solve various real-world problems such as fraud detection,
spam filtering, etc.
Disadvantages of supervised learning:
- Supervised learning models
are not suitable for handling the complex tasks.
- Supervised learning cannot
predict the correct output if the test data is different from the training
dataset.
- Training required lots of
computation times.
- In supervised learning, we
need enough knowledge about the classes of object.
2.Unsupervised Machine Learning
In the previous topic, we learned supervised
machine learning in which models are trained using labeled data under the
supervision of training data. But there may be many cases in which we do not
have labeled data and need to find the hidden patterns from the given dataset.
So, to solve such types of cases in machine learning, we need unsupervised
learning techniques.
What is Unsupervised Learning?
As the name suggests, unsupervised learning
is a machine learning technique in which models are not supervised using training
dataset. Instead, models itself find the hidden patterns and insights from the
given data. It can be compared to learning which takes place in the human brain
while learning new things. It can be defined as:
Unsupervised
learning is a type of machine learning in which models are trained using
unlabeled dataset and are allowed to act on that data without any supervision.
Unsupervised learning cannot be directly
applied to a regression or classification problem because unlike supervised
learning, we have the input data but no corresponding output data. The goal of
unsupervised learning is to find the underlying structure of dataset,
group that data according to similarities, and represent that dataset in a
compressed format.
Example: Suppose the unsupervised learning algorithm is given
an input dataset containing images of different types of cats and dogs. The
algorithm is never trained upon the given dataset, which means it does not have
any idea about the features of the dataset. The task of the unsupervised
learning algorithm is to identify the image features on their own. Unsupervised
learning algorithm will perform this task by clustering the image dataset into
the groups according to similarities between images.
Why use Unsupervised Learning?
Below are some main reasons which describe
the importance of Unsupervised Learning:
- Unsupervised
learning is helpful for finding useful insights from the data.
- Unsupervised
learning is much similar as a human learns to think by their own
experiences, which makes it closer to the real AI.
- Unsupervised
learning works on unlabeled and uncategorized data which make unsupervised
learning more important.
- In
real-world, we do not always have input data with the corresponding output
so to solve such cases, we need unsupervised learning.
Working of Unsupervised Learning
Working of unsupervised learning can be
understood by the below diagram:
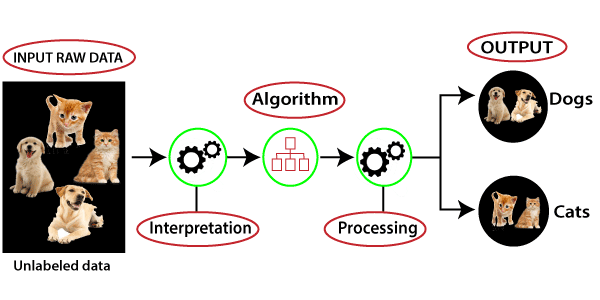
Here, we have taken an unlabeled input data,
which means it is not categorized and corresponding outputs are also not given.
Now, this unlabeled input data is fed to the machine learning model in order to
train it. Firstly, it will interpret the raw data to find the hidden patterns
from the data and then will apply suitable algorithms such as k-means
clustering, Decision tree, etc.
Once it applies the suitable algorithm, the
algorithm divides the data objects into groups according to the similarities
and difference between the objects.
Types of Unsupervised Learning Algorithm:
The unsupervised learning algorithm can be
further categorized into two types of problems:
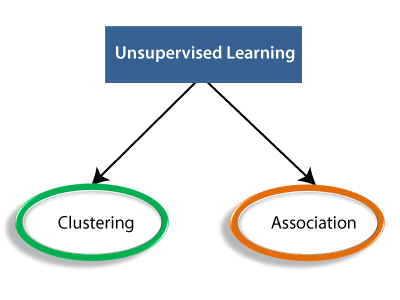
- Clustering: Clustering is a method of
grouping the objects into clusters such that objects with most similarities
remains into a group and has less or no similarities with the objects of
another group. Cluster analysis finds the commonalities between the data
objects and categorizes them as per the presence and absence of those
commonalities.
- Association: An
association rule is an unsupervised learning method which is used for
finding the relationships between variables in the large database. It
determines the set of items that occurs together in the dataset.
Association rule makes marketing strategy more effective. Such as people
who buy X item (suppose a bread) are also tend to purchase Y (Butter/Jam)
item. A typical example of Association rule is Market Basket Analysis.
Unsupervised Learning algorithms:
Below is the list of some popular
unsupervised learning algorithms:
- K-means clustering
- KNN (k-nearest neighbors)
- Hierarchal clustering
- Anomaly detection
- Neural Networks
- Principle Component Analysis
- Independent Component Analysis
- Apriori algorithm
- Singular value decomposition
Advantages of Unsupervised Learning
- Unsupervised
learning is used for more complex tasks as compared to supervised learning
because, in unsupervised learning, we don't have labeled input data.
- Unsupervised
learning is preferable as it is easy to get unlabeled data in comparison
to labeled data.
Disadvantages of Unsupervised Learning
- Unsupervised
learning is intrinsically more difficult than supervised learning as it
does not have corresponding output.
- The result of
the unsupervised learning algorithm might be less accurate as input data
is not labeled, and algorithms do not know the exact output in advance.
3.Reinforcement Learning
- Reinforcement
Learning is a feedback-based Machine learning technique in which an agent
learns to behave in an environment by performing the actions and seeing
the results of actions. For each good action, the agent gets positive
feedback, and for each bad action, the agent gets negative feedback or
penalty.
- In
Reinforcement Learning, the agent learns automatically using feedbacks
without any labeled data, unlike Supervised learning
- Since there
is no labeled data, so the agent is bound to learn by its experience only.
- RL solves a
specific type of problem where decision making is sequential, and the goal
is long-term, such as game-playing, robotics, etc.
- The agent
interacts with the environment and explores it by itself. The primary goal
of an agent in reinforcement learning is to improve the performance by
getting the maximum positive rewards.
- The agent
learns with the process of hit and trial, and based on the experience, it
learns to perform the task in a better way. Hence, we can say that "Reinforcement
learning is a type of machine learning method where an intelligent agent
(computer program) interacts with the environment and learns to act within
that." How a Robotic dog learns the movement of his arms is
an example of Reinforcement learning.
- It is a core
part ofArtificial Learning, and all AI agent works on the concept of
reinforcement learning. Here we do not need to pre-program the agent, as
it learns from its own experience without any human intervention.
- Example: Suppose there is an AI agent
present within a maze environment, and his goal is to find the diamond.
The agent interacts with the environment by performing some actions, and
based on those actions, the state of the agent gets changed, and it also
receives a reward or penalty as feedback.
- The agent
continues doing these three things (take action, change
state/remain in the same state, and get feedback), and by doing
these actions, he learns and explores the environment.
- The agent
learns that what actions lead to positive feedback or rewards and what
actions lead to negative feedback penalty. As a positive reward, the agent
gets a positive point, and as a penalty, it gets a negative point.
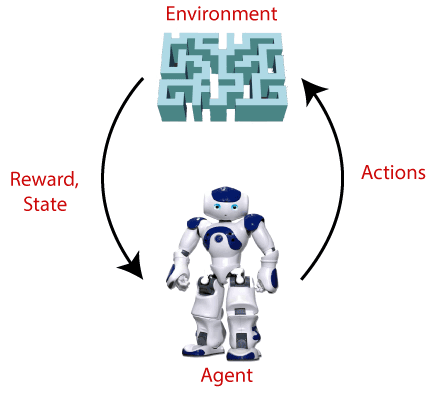
Terms used in Reinforcement Learning
- Agent(): An entity that can
perceive/explore the environment and act upon it.
- Environment(): A situation
in which an agent is present or surrounded by. In RL, we assume the
stochastic environment, which means it is random in nature.
- Action(): Actions are the moves taken
by an agent within the environment.
- State(): State is a situation returned
by the environment after each action taken by the agent.
- Reward(): A feedback returned to the
agent from the environment to evaluate the action of the agent.
- Policy(): Policy is a strategy applied
by the agent for the next action based on the current state.
- Value(): It is expected long-term
retuned with the discount factor and opposite to the short-term reward.
- Q-value(): It is mostly similar to the
value, but it takes one additional parameter as a current action (a).
Key Features of Reinforcement Learning
- In RL, the
agent is not instructed about the environment and what actions need to be
taken.
- It is based
on the hit and trial process.
- The agent
takes the next action and changes states according to the feedback of the
previous action.
- The agent may
get a delayed reward.
- The
environment is stochastic, and the agent needs to explore it to reach to
get the maximum positive rewards.
Approaches to implement Reinforcement
Learning
There are mainly three ways to implement
reinforcement-learning in ML, which are:
1.
Value-based:
The value-based approach is about to find the optimal value function, which is
the maximum value at a state under any policy. Therefore, the agent expects the
long-term return at any state(s) under policy π.
2.
Policy-based:
Policy-based approach is to find the optimal policy for the maximum future
rewards without using the value function. In this approach, the agent tries to
apply such a policy that the action performed in each step helps to maximize
the future reward.
The policy-based approach has mainly two types of policy:
o
Deterministic: The same action
is produced by the policy (π) at any state.
o
Stochastic: In this policy,
probability determines the produced action.
3.
Model-based: In the
model-based approach, a virtual model is created for the environment, and the
agent explores that environment to learn it. There is no particular solution or
algorithm for this approach because the model representation is different for
each environment.
Elements of Reinforcement Learning
There are four main elements of Reinforcement
Learning, which are given below:
1.
Policy
2.
Reward
Signal
3.
Value
Function
4.
Model
of the environment
1) Policy: A policy can be defined as a way how an agent behaves
at a given time. It maps the perceived states of the environment to the actions
taken on those states. A policy is the core element of the RL as it alone can
define the behavior of the agent. In some cases, it may be a simple function or
a lookup table, whereas, for other cases, it may involve general computation as
a search process. It could be deterministic or a stochastic policy:
For deterministic policy: a = π(s)
For stochastic policy: π(a | s) = P[At =a | St = s]
2) Reward Signal: The goal of reinforcement learning is defined by the
reward signal. At each state, the environment sends an immediate signal to the
learning agent, and this signal is known as a reward signal.
These rewards are given according to the good and bad actions taken by the
agent. The agent's main objective is to maximize the total number of rewards
for good actions. The reward signal can change the policy, such as if an action
selected by the agent leads to low reward, then the policy may change to select
other actions in the future.
3) Value Function: The value function gives information about how good
the situation and action are and how much reward an agent can expect. A reward
indicates the immediate signal for each good and bad action,
whereas a value function specifies the good state and action for the
future. The value function depends on the reward as, without reward,
there could be no value. The goal of estimating values is to achieve more
rewards.
4) Model: The last element of reinforcement learning is the
model, which mimics the behavior of the environment. With the help of the
model, one can make inferences about how the environment will behave. Such as,
if a state and an action are given, then a model can predict the next state and
reward.
The model is used for planning, which means
it provides a way to take a course of action by considering all future
situations before actually experiencing those situations. The approaches for
solving the RL problems with the help of the model are termed
as the model-based approach. Comparatively, an approach without
using a model is called a model-free approach.
List of Popular Machine Learning Algorithm
1. Linear Regression Algorithm
2. Logistic Regression Algorithm
3. Decision Tree
4. SVM
5. Naïve Bayes
6. KNN
7. K-Means Clustering
8. Random Forest
1. Linear Regression
Linear regression is one of the most popular
and simple machine learning algorithms that is used for predictive analysis.
Here, predictive analysis defines prediction of something, and
linear regression makes predictions for continuous numbers such as salary,
age, etc.
It shows the linear relationship between the
dependent and independent variables, and shows how the dependent variable(y)
changes according to the independent variable (x).
It tries to best fit a line between the
dependent and independent variables, and this best fit line is knowns as the
regression line.
The equation for the regression line is:
y= a0+ a*x+ b
Here, y= dependent variable
x= independent variable
a0 = Intercept of line.
Linear regression is further divided into two
types:
- Simple Linear Regression: In simple
linear regression, a single independent variable is used to predict the
value of the dependent variable.
- Multiple Linear Regression: In multiple
linear regression, more than one independent variables are used to predict
the value of the dependent variable.
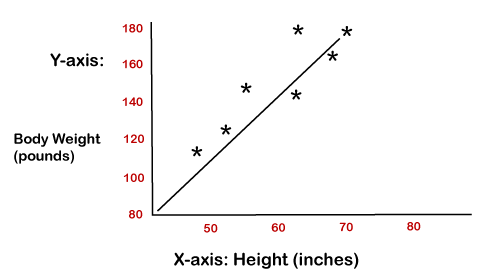
The below diagram shows the linear regression
for prediction of weight according to height:
2. Logistic Regression
- Logistic
regression is one of the most popular Machine Learning algorithms, which
comes under the Supervised Learning technique. It is used for predicting
the categorical dependent variable using a given set of independent
variables.
- Logistic
regression predicts the output of a categorical dependent variable.
Therefore the outcome must be a categorical or discrete value. It can be
either Yes or No, 0 or 1, true or False, etc. but instead of giving the
exact value as 0 and 1, it gives the probabilistic values which
lie between 0 and 1.
- Logistic
Regression is much similar to the Linear Regression except that how they
are used. Linear Regression is used for solving Regression problems,
whereas Logistic regression is used for solving the classification
problems.
- In Logistic
regression, instead of fitting a regression line, we fit an "S"
shaped logistic function, which predicts two maximum values (0 or 1).
- The curve
from the logistic function indicates the likelihood of something such as
whether the cells are cancerous or not, a mouse is obese or not based on
its weight, etc.
- Logistic
Regression is a significant machine learning algorithm because it has the
ability to provide probabilities and classify new data using continuous
and discrete datasets.
- Logistic
Regression can be used to classify the observations using different types
of data and can easily determine the most effective variables used for the
classification. The below image is showing the logistic function:
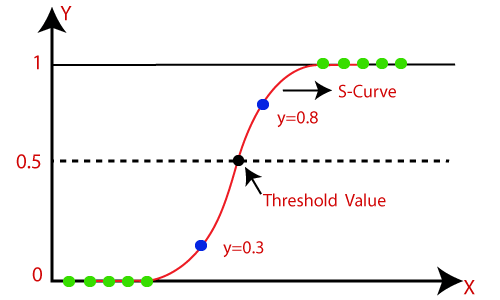
Logistic Function (Sigmoid Function):
- The sigmoid
function is a mathematical function used to map the predicted values to
probabilities.
- It maps any
real value into another value within a range of 0 and 1.
- The value of
the logistic regression must be between 0 and 1, which cannot go beyond
this limit, so it forms a curve like the "S" form. The S-form
curve is called the Sigmoid function or the logistic function.
- In logistic
regression, we use the concept of the threshold value, which defines the
probability of either 0 or 1. Such as values above the threshold value
tends to 1, and a value below the threshold values tends to 0.
Assumptions for Logistic Regression:
- The dependent
variable must be categorical in nature.
- The
independent variable should not have multi-collinearity.
Type of Logistic Regression:
On the basis of the categories, Logistic
Regression can be classified into three types:
- Binomial: In binomial Logistic
regression, there can be only two possible types of the dependent
variables, such as 0 or 1, Pass or Fail, etc.
- Multinomial: In
multinomial Logistic regression, there can be 3 or more possible unordered
types of the dependent variable, such as "cat",
"dogs", or "sheep"
- Ordinal: In ordinal Logistic
regression, there can be 3 or more possible ordered types of dependent
variables, such as "low", "Medium", or
"High".
3.Decision Trees
- Decision Tree
is a Supervised learning technique that can be used for
both classification and Regression problems, but mostly it is preferred
for solving Classification problems. It is a tree-structured classifier,
where internal nodes represent the features of a dataset, branches
represent the decision rules and each leaf node
represents the outcome.
- In a Decision
tree, there are two nodes, which are the Decision Node
and Leaf Node. Decision nodes are used to make any
decision and have multiple branches, whereas Leaf nodes are the output of
those decisions and do not contain any further branches.
- The decisions
or the test are performed on the basis of features of the given dataset.
- It is a graphical representation for getting all
the possible solutions to a problem/decision based on given conditions.
- It is called
a decision tree because, similar to a tree, it starts with the root node,
which expands on further branches and constructs a tree-like structure.
- In order to
build a tree, we use the CART algorithm, which stands for
Classification and Regression Tree algorithm.
- A decision
tree simply asks a question, and based on the answer (Yes/No), it further
split the tree into subtrees.
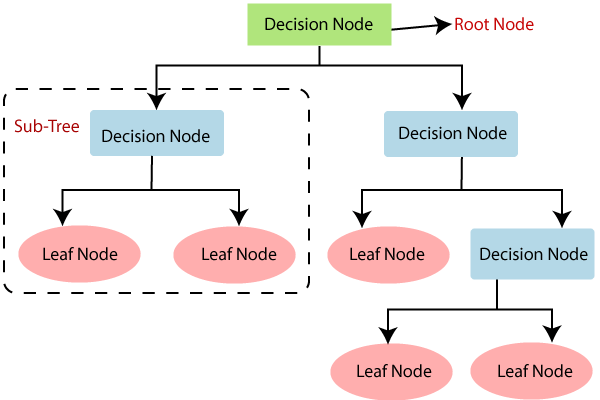
- Below diagram
explains the general structure of a decision tree:
Why use Decision Trees?
There are various algorithms in Machine
learning, so choosing the best algorithm for the given dataset and problem is
the main point to remember while creating a machine learning model. Below are
the two reasons for using the Decision tree:
- Decision
Trees usually mimic human thinking ability while making a decision, so it
is easy to understand.
- The logic
behind the decision tree can be easily understood because it shows a
tree-like structure.
Decision Tree Terminologies
Root
Node: Root node is from where the decision tree starts. It represents
the entire dataset, which further gets divided into two or more homogeneous
sets.
Leaf
Node: Leaf nodes are the final output node, and the tree cannot be
segregated further after getting a leaf node.
Splitting:
Splitting is the process of dividing the decision node/root node into sub-nodes
according to the given conditions.
Branch/Sub
Tree: A tree formed by splitting the tree.
Pruning:
Pruning is the process of removing the unwanted branches from the tree.
Parent/Child
node: The root node of the tree is called the parent node, and other
nodes are called the child nodes.
4.SVM
Support
Vector Machine or SVM is one of the most popular Supervised Learning
algorithms, which is used for Classification as well as Regression problems.
However, primarily, it is used for Classification problems in Machine Learning.
The goal
of the SVM algorithm is to create the best line or decision boundary that can
segregate n-dimensional space into classes so that we can easily put the new
data point in the correct category in the future. This best decision boundary
is called a hyperplane.
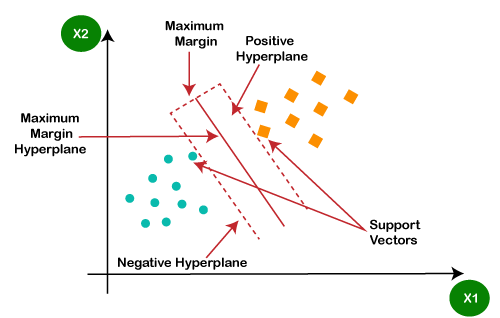
SVM
chooses the extreme points/vectors that help in creating the hyperplane. These
extreme cases are called as support vectors, and hence algorithm is termed as
Support Vector Machine. Consider the below diagram in which there are two
different categories that are classified using a decision boundary or
hyperplane:
Example: SVM can be understood with the
example that we have used in the KNN classifier. Suppose we see a strange cat
that also has some features of dogs, so if we want a model that can accurately
identify whether it is a cat or dog, so such a model can be created by using
the SVM algorithm. We will first train our model with lots of images of cats
and dogs so that it can learn about different features of cats and dogs, and
then we test it with this strange creature. So as support vector creates a
decision boundary between these two data (cat and dog) and choose extreme cases
(support vectors), it will see the extreme case of cat and dog. On the basis of
the support vectors, it will classify it as a cat. Consider the below diagram:
SVM
algorithm can be used for Face detection, image classification, text
categorization, etc.
Types of SVM
SVM can
be of two types:
- Linear SVM: Linear SVM is used for
linearly separable data, which means if a dataset can be classified into
two classes by using a single straight line, then such data is termed as
linearly separable data, and classifier is used called as Linear SVM
classifier.
- Non-linear SVM: Non-Linear SVM is used for
non-linearly separated data, which means if a dataset cannot be classified
by using a straight line, then such data is termed as non-linear data and
classifier used is called as Non-linear SVM classifier.
5.
Naïve Bayes Algorithm:
Naïve Bayes classifier is a supervised
learning algorithm, which is used to make predictions based on the probability
of the object. The algorithm named as Naïve Bayes as it is based on Bayes
theorem, and follows the naïve assumption that says' variables
are independent of each other.
The Bayes theorem is based on the conditional
probability; it means the likelihood that event(A) will happen, when it is
given that event(B) has already happened. The equation for Bayes theorem is
given as:
Naïve Bayes classifier is one of the best
classifiers that provide a good result for a given problem. It is easy to build
a naïve bayesian model, and well suited for the huge amount of dataset. It is
mostly used for text classification.
6.KNN
- K-Nearest Neighbour is one
of the simplest Machine Learning algorithms based on Supervised Learning
technique.
- K-NN algorithm assumes the
similarity between the new case/data and available cases and put the new
case into the category that is most similar to the available categories.
- K-NN algorithm stores all
the available data and classifies a new data point based on the
similarity. This means when new data appears then it can be easily
classified into a well suite category by using K- NN algorithm.
- K-NN algorithm can be used
for Regression as well as for Classification but mostly it is used for the
Classification problems.
- K-NN is a non-parametric
algorithm, which means it does not make any assumption on underlying
data.
- It is also called a lazy
learner algorithm because it does not learn from the training set
immediately instead it stores the dataset and at the time of
classification, it performs an action on the dataset.
- KNN algorithm at the
training phase just stores the dataset and when it gets new data, then it
classifies that data into a category that is much similar to the new data.
- Example: Suppose, we have an image
of a creature that looks similar to cat and dog, but we want to know
either it is a cat or dog. So for this identification, we can use the KNN
algorithm, as it works on a similarity measure. Our KNN model will find
the similar features of the new data set to the cats and dogs images and
based on the most similar features it will put it in either cat or dog
category.

7. K-Means Clustering
K-means clustering is one of the simplest
unsupervised learning algorithms, which is used to solve the clustering
problems. The datasets are grouped into K different clusters based on
similarities and dissimilarities, it means, datasets with most of the commonalties
remain in one cluster which has very less or no commonalities between other
clusters. In K-means, K-refers to the number of clusters, and means
refer to the averaging the dataset in order to find the centroid.
It is a centroid-based algorithm, and each
cluster is associated with a centroid. This algorithm aims to reduce the
distance between the data points and their centroids within a cluster.
This algorithm starts with a group of
randomly selected centroids that form the clusters at starting and then perform
the iterative process to optimize these centroids' positions.
It can be used for spam detection and
filtering, identification of fake news, etc.
8. Random Forest Algorithm
Random forest is the supervised learning
algorithm that can be used for both classification and regression problems in
machine learning. It is an ensemble learning technique that provides the
predictions by combining the multiple classifiers and improve the performance
of the model.
It contains multiple decision trees for subsets
of the given dataset, and find the average to improve the predictive accuracy
of the model. A random-forest should contain 64-128 trees. The greater number
of trees leads to higher accuracy of the algorithm.
To classify a new dataset or object, each
tree gives the classification result and based on the majority votes, the
algorithm predicts the final output.
Random forest is a fast algorithm, and can
efficiently deal with the missing & incorrect data.
Conclusion :
Machine
Learning can be a Supervised or Unsupervised. If you have lesser amount of data
and clearly labelled data for training, opt for Supervised Learning.
Unsupervised Learning would generally give better performance and results for
large data sets. If you have a huge data set easily available, go for deep
learning techniques. You also have learned Reinforcement Learning and Deep
Reinforcement Learning. You now know what Neural Networks are, their
applications and limitations.
Finally,
when it comes to the development of machine learning models of your own, you
looked at the choices of various development languages, IDEs and Platforms.
Next thing that you need to do is start learning and practicing each machine
learning technique. The subject is vast, it means that there is width, but if
you consider the depth, each topic can be learned in a few hours. Each topic is
independent of each other. You need to take into consideration one topic at a
time, learn it, practice it and implement the algorithm/s in it using a
language choice of yours. This is the best way to start studying Machine
Learning. Practicing one topic at a time, very soon you would acquire the width
that is eventually required of a Machine Learning expert.
Informative
ReplyDelete